 The AMD OpenCL coding competition seems to be Windows 7 64bit only. So if you are on another version of Windows, OSX or (like me) on Linux, you are left behind. Of course StreamHPC supports software that just works anywhere (seriously, how hard is that nowadays?), so here are the instructions how to enter the competition when you work with Eclipse CDT. The reason why it only works with 64-bit Windows I don’t really get (but I understood it was a hint).
The AMD OpenCL coding competition seems to be Windows 7 64bit only. So if you are on another version of Windows, OSX or (like me) on Linux, you are left behind. Of course StreamHPC supports software that just works anywhere (seriously, how hard is that nowadays?), so here are the instructions how to enter the competition when you work with Eclipse CDT. The reason why it only works with 64-bit Windows I don’t really get (but I understood it was a hint).
I focused on Linux, so it might not work with Windows XP or OSX rightaway. With little hacking, I’m sure you can change the instructions to work with i.e. Xcode or any other IDE which can import C++-projects with makefiles. Let me know if it works for you and what you changed.


 Update: we are very sorry to tell that due to a deadline in a project we were forced to cancel Vincent’s talk.
Update: we are very sorry to tell that due to a deadline in a project we were forced to cancel Vincent’s talk. Big data is a term for data so large or complex that traditional processing applications are inadequate. Challenges include:
Big data is a term for data so large or complex that traditional processing applications are inadequate. Challenges include:
 The information you find everywhere: on Linux the current “radeon” and “fglrx” are being replaced by AMDGPU (graphics) and ROCm (compute) for HSA-enabled GPUs. As the whole AMD Linux driver team is seemingly working on getting the new and open source drivers ready, fglrx is now deprecated and will not get updates (or very late). I therefore can get to the point:
The information you find everywhere: on Linux the current “radeon” and “fglrx” are being replaced by AMDGPU (graphics) and ROCm (compute) for HSA-enabled GPUs. As the whole AMD Linux driver team is seemingly working on getting the new and open source drivers ready, fglrx is now deprecated and will not get updates (or very late). I therefore can get to the point:




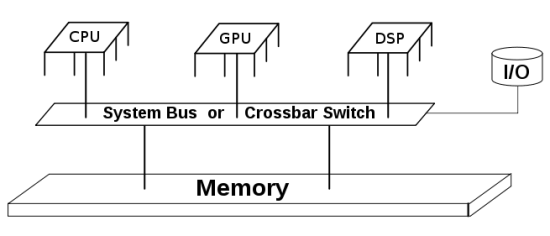


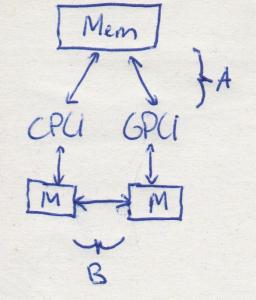
 See the difference?
See the difference?









 Answer: Yes, actually a lot!
Answer: Yes, actually a lot!
 The main strength of Artificial Intelligence is it’s easy to understand by anybody. This results in new applications in all industries at a rapid pace. Are there new possibilities generated or have the possibilities always been possible? The answer is both.
The main strength of Artificial Intelligence is it’s easy to understand by anybody. This results in new applications in all industries at a rapid pace. Are there new possibilities generated or have the possibilities always been possible? The answer is both.

