

Update: C++ has been moved from OpenCL 2.1 to 2.2, being released in 2017. Title and text have been updated to reflect this. A reason why Apple released Metal might be the reason that Khronos was too slow in releasing C++ kernels into OpenCL, given the delays.
Apple Metal in one sentence: one queue for both OpenCL and OpenGL, using C++11. They now brought it to OSX. The detail they don’t tell: that’s exactly what the combination of Vulkan + OpenCL 2.1 2.2 does. Instead it is compared with OpenCL 1.x + OpenGL 4.x, which it certainly can compete with, as that combination doesn’t have C++11 kernels nor a single queue.
Apple Metal on OSX – a little too late, bringing nothing new to the stage, compared to SPIR and OpenCL
2.12.2.
The main reason why they can’t compete with the standards, is that there is an urge to create high-level languages and DSLs on top of lower-level languages. What Apple did, was to create just one and leaving out the rest. This means that languages like SYCL and C++AMP (implemented on top of SPIR-V) can’t simply run on OSX, and thus blocking new innovations. To understand why SPIR-V is so important and Apple should adopt for that road, read this article on SPIR-V.

Yet another vendor lock-in?
Now Khronos is switching its two most important APIs to the next level, there is a short-term void. This is clearly the right moment for Apple to take the risk and trying to get developers interested in their new language. If they succeed, then we get the well-known “pffff, I have no time to port it to other platforms” and there is a win for Apple’s platforms (they hope).
Apple has always wanted to have a different way of interacting with OpenCL-kernels using Grand Central Dispatch. Porting OpenCL between Linux and Windows is a breeze, but from and to OSX is not. Discussions over the past years with many people from the industry thought me one thing: Apple is like Google, Microsoft and NVidia – they don’t really want standards, but want 100% dedicated developers for their languages.
Yes, now also Apple is on the list of Me-too™ languages for OpenCL. We at StreamHPC can easily translate your code from and too Metal, but we would like it that you can put your investments in more important matters like improving the algorithms and performance.
Still OpenCL support on OSX?
Yes, but only OpenCL 1.2. A way to work around is to use SPIR-to-Metal translators and a wrapper from Vulkan to Metal – this will not make it very convenient though. The way to go, is that everybody starts asking for OpenCL 2.0 support on OSX forums. Metal is a great API, but that doesn’t change the fact it’s obstructing standardisation of likewise great, open standards. If they provide both Metal and Vulkan+OpenCL 2.1 2.2 then I am happy – then the developers have the choice.
Metal debuts in “OSX El Capitan”, which is available per today to developers, and this fall to the general public.

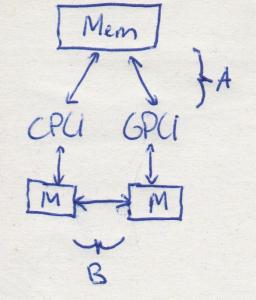
 See the difference?
See the difference?

 The information you find everywhere: on Linux the current “radeon” and “fglrx” are being replaced by AMDGPU (graphics) and ROCm (compute) for HSA-enabled GPUs. As the whole AMD Linux driver team is seemingly working on getting the new and open source drivers ready, fglrx is now deprecated and will not get updates (or very late). I therefore can get to the point:
The information you find everywhere: on Linux the current “radeon” and “fglrx” are being replaced by AMDGPU (graphics) and ROCm (compute) for HSA-enabled GPUs. As the whole AMD Linux driver team is seemingly working on getting the new and open source drivers ready, fglrx is now deprecated and will not get updates (or very late). I therefore can get to the point:
 Big data is a term for data so large or complex that traditional processing applications are inadequate. Challenges include:
Big data is a term for data so large or complex that traditional processing applications are inadequate. Challenges include:




 e-mail:
e-mail: 

 When CUDA kept having a dominance over OpenCL, AMD introduced HIP – a programming language that closely resembles CUDA. Now it doesn’t take months to port code to AMD hardware, but more and more CUDA-software converts to HIP without problems. The real large and complex code-bases only take a few weeks max, where we found that solved problems also made the CUDA-code run faster.
When CUDA kept having a dominance over OpenCL, AMD introduced HIP – a programming language that closely resembles CUDA. Now it doesn’t take months to port code to AMD hardware, but more and more CUDA-software converts to HIP without problems. The real large and complex code-bases only take a few weeks max, where we found that solved problems also made the CUDA-code run faster. In the release notes for 378.66 graphics drivers for Windows (February 2017), NVIDIA officially spoke about supporting OpenCL 2.0 for the first time. Unfortunately, this is partial support only and, as NVIDIA said, these new [OpenCL 2.0] features are available for evaluation purposes only.
In the release notes for 378.66 graphics drivers for Windows (February 2017), NVIDIA officially spoke about supporting OpenCL 2.0 for the first time. Unfortunately, this is partial support only and, as NVIDIA said, these new [OpenCL 2.0] features are available for evaluation purposes only.

 For who hasn’t seen the latest addition to our knowledge base, we have added a list of all (almost) available OpenCL-SDKs. You can find it in the menu under “Knowledge Base” -> “
For who hasn’t seen the latest addition to our knowledge base, we have added a list of all (almost) available OpenCL-SDKs. You can find it in the menu under “Knowledge Base” -> “









 At Intel they have CPUs (Xeon, Ivy Bridge), GPUs (Isis) and Accelerators (Xeon Phi). OpenCL enables each processor to be used to the fullest and they now promote it as such. Watch the below video and see their view on why OpenCL makes a difference for Intel’s customers.
At Intel they have CPUs (Xeon, Ivy Bridge), GPUs (Isis) and Accelerators (Xeon Phi). OpenCL enables each processor to be used to the fullest and they now promote it as such. Watch the below video and see their view on why OpenCL makes a difference for Intel’s customers.