More and more professional media software now has support for OpenCL. It starts to be a race where you cannot stay behind. If the competitor runs more than twice as fast on the same hardware, then you just can’t say “Sorry, you should buy NVIDIA hardware”. I expected this to happen, but could not tell in what industry they would run fastest. Seems it is fluid dynamics, video-editors and photo-editors.
AMD and Intel mostly have been selected as collaboration partners. Apple has been a main drive, especially with the introduction of their new MAC Pro with two high-end AMD FirePro GPUs.
Sony Catalyst Family
Sony released three new software packages to support video professionals in pre- and post-production.

This new family of products, Catalyst Browse (media management), Catalyst Prepare (video preproduction assistant) and Catalyst Edit (4K and Sony RAW video editing) has OpenCL support from the start.
Colorfront Express Dailies and On-Set Dailies
This software is an on-set dailies processing system (playback and sync, QC, colour grading, audio and metadata management).
The 2014 versions have OpenCL support in their transcoder plugin, Transkoder.

RED REDCINE-X PRO

REDCINE-X is a coloring toolset, integrated timeline, and post effects collection in a professional, flexible environment for your 4K or 5K .R3D files. RED has added support for OpenCL in build 22.
The Foundry Nuke Blink framework
As presented on GPUconf, The Foundry has opened their framework for running OpenCL kernels. It creates OpenCL-kernels (optimised for AMD or NVIDIA) from C++ Blink kernels.

NUKE studio is a node-based VFX, editorial and finishing studio. As with most products on this page, look for the “reel” to get a nice demo of its capabilities.
Magix Hybrid Video Engine
Video Deluxe and Movie Edit both have OpenCL support since 2012, thanks to the new shared video engine.
Adobe CS6 creative suite
Adobe has entered the OpenCL market publicly with . With Premiere Pro (video editing) and Photoshop (photo-editing) two main products with advanced GPU-acceleration via OpenCL.
Video on GPU-effects on Premiere Pro CS5.
FAQ on GPU-acceleration on Photoshop CS6.
Sony Vegas Pro
Vegas Pro is a video editing software package for non-linear editing systems, and has OpenCL support since version 10d. Also in the consumer version (Sony Movie Studio) there is OpenCL-support.

RealFlow Hybrido2 engine
RealFlow is fluid dynamics software and its new engine Hybrido2 has support for OpenCL since this year. And you just have to love their commercial videos.
Autodesk Maya
Maya is a toolsets to help create and maintain the modern, open pipelines you need to address today’s challenging 3D animation, visual effects, game development and post-production projects. Since the 2013 version it is accelerated for physics simulations via Bullet and OpenCL.
ArcSoft SimHD and Sim3D engine
ArcSoft media-engines SimHD and Sim3D have OpenCL support since several years and are used in several of their products.

BlackMagic Design
BMD has two suites which use OpenCL, Resolve and Fusion. DaVinci was acquired in 2009 and EyeOn in 2014.
(DaVinci) Resolve
Resolve has real-time colour correction thanks to OpenCL.
(Eyeon) Fusion

Fusion is an image compositing software program created by eyeon Software Inc. It is typically used to create visual effects and digital compositing for film, HD and commercials.
It uses OpenCL since version 6.
Roxio Creator Suite
Roxio uses OpenCL for accelerated rendering in their suite. They were one of the first to implement OpenCL – I think already in 2010, before OpenCL was even cool.

Unluckily they don’t have much information – just a mention that they have support.
Apple Final Cut Pro and iMovie
Apple has support in Final Cut Pro X, Motion 5 and Compressor 4.

Also iMovie works a lot faster when you have an OpenCL capable MAC.
Blender Cycles & Bullet
You cannot find any demonstration of new video hardware without Big Bucks Bunny, the short CG movie created with Blender.
It uses OpenCL in two parts: physics simulations (Bullet) and compositor (Cycles).
Side Effects Houdini
Houdini is a procedural node based 3D animation and visual effects tools for film, broadcast, entertainment and visualisation production.
 DigitalFilmTools
DigitalFilmTools
There is support for OpenCL in zMatte, Composite Suite Pro and Film Stocks since Q4 2013.
zMatte is a keyer for blue and green screen composites. Composite Suite Pro is a collection of visual effects plug-ins. Film Stocks simulates color and black and white still photographic film stocks, motion picture films stocks and historical photographic processes.
OTOY OctaneRender 3
OctaneRender is a GPU-based, real-time 3D, unbiased rendering application. In March 2015 OTOY announced OctaneRender 3, which has full OpenCL support:
OpenCL support: OctaneRender 3 will support the broadest range of processors possible using OpenCL to run on Intel CPUs with support for out-of-core geometry, OpenCL FPGAs and ASICs, and AMD GPUs.
Below is a reel of OcateRender 2 with CUDA. According to OTOY the performance on AMD and NVidia is comparable.
SAM Alchemist XF

Alchemist XF supports format and framerate conversion from SD up to 4K for a wide variety of file formats at high speed.
More?
There is a lot more OpenCL-powered software coming up rapidly (we hear things). But we also missed (or accidentally forgot) software. Please help making this list complete and send us an email.

 OpenCL SPIR (Standard Portable Intermediate Representation) is an intermediate representation for OpenCL-code, comparable to LLVM IL and HSAIL. It is a search for what would be a good representation, such that parallel software runs well on all kinds of accelerators. LLVM IL is too general, but SPIR is a subset of it. I’ll discuss HSAIL, on where it differs from SPIR – I thought SPIR was a better way to start introducing these. In my next article I’d like to give you an overview of the whole ecosphere around OpenCL (including SPIR and HSAIL), to give you an understanding what it all means and where we’re going to, and why.
OpenCL SPIR (Standard Portable Intermediate Representation) is an intermediate representation for OpenCL-code, comparable to LLVM IL and HSAIL. It is a search for what would be a good representation, such that parallel software runs well on all kinds of accelerators. LLVM IL is too general, but SPIR is a subset of it. I’ll discuss HSAIL, on where it differs from SPIR – I thought SPIR was a better way to start introducing these. In my next article I’d like to give you an overview of the whole ecosphere around OpenCL (including SPIR and HSAIL), to give you an understanding what it all means and where we’re going to, and why.
















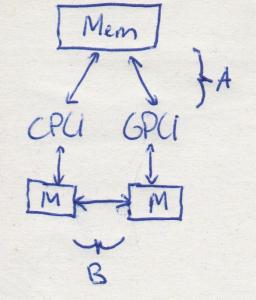
 See the difference?
See the difference?


 Let the competition on large memory GPUs begin!
Let the competition on large memory GPUs begin!
















 The past year you might not have heard much from OpenCL-on-ARM, besides the Arndale developer-board. You have heard just a small portion of what has been going on.
The past year you might not have heard much from OpenCL-on-ARM, besides the Arndale developer-board. You have heard just a small portion of what has been going on.



