During SC14 (SuperComputing Conference 2014), OpenCL is again all over New Orleans. Just like last year, I’ve composed an overview based on info from the Khronos website and the SC2014 website.
During SC14 (SuperComputing Conference 2014), OpenCL is again all over New Orleans. Just like last year, I’ve composed an overview based on info from the Khronos website and the SC2014 website.
Finally I’m attending SC14 myself, and will give two talks for you. Tuesday I’ll be part of a 90 minute session of Khronos, where I’ll talk a bit about GROMACS and selecting the right accelerator for your software. Wednesday I’ll be sharing our experiences from our port of GROMACS to OpenCL. If you meet me, then I can hand you over a leaflet with the decision chart to help select the best device for the job.











 The research lab
The research lab 
 Altera has just released the free ebook FPGAs for dummies. One part of the book is devoted to OpenCL, so we’ll quote some extracts here from one of the chapters. The rest of the book is worth a read, so if you want to check the rest of the text, just
Altera has just released the free ebook FPGAs for dummies. One part of the book is devoted to OpenCL, so we’ll quote some extracts here from one of the chapters. The rest of the book is worth a read, so if you want to check the rest of the text, just 

 When copying data from global to local memory, you often see code like below (1D data):
When copying data from global to local memory, you often see code like below (1D data):



 So, for this year it will be K40. Here’s an overview:
So, for this year it will be K40. Here’s an overview:

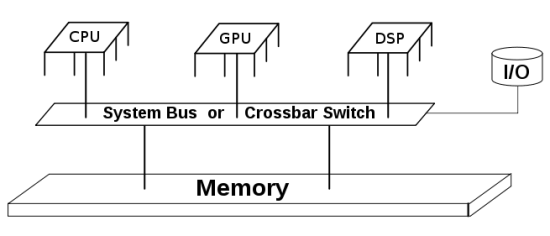
 At Intel they have CPUs (Xeon, Ivy Bridge), GPUs (Isis) and Accelerators (Xeon Phi). OpenCL enables each processor to be used to the fullest and they now promote it as such. Watch the below video and see their view on why OpenCL makes a difference for Intel’s customers.
At Intel they have CPUs (Xeon, Ivy Bridge), GPUs (Isis) and Accelerators (Xeon Phi). OpenCL enables each processor to be used to the fullest and they now promote it as such. Watch the below video and see their view on why OpenCL makes a difference for Intel’s customers.
 Khronos just announced three OpenCL based releases:
Khronos just announced three OpenCL based releases: