Using unused processing power
The computer as we know it has changed a lot since the past years. For instance, we now can use the graphics card for non-graphic purposes. This has resulted in a computer with a much higher potential. Doubling of processing-speed or more is more rule than exception. Using this unused extra speed gives a huge advantage to software which makes use of it – and that explains the growing popularity.
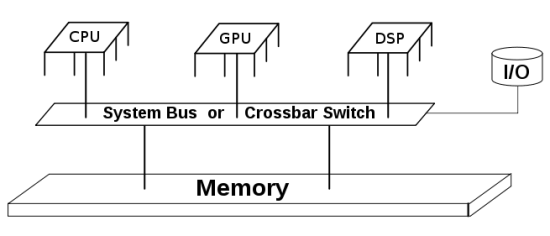
The acceleration-technique is called OpenCL and not only works on graphics cards of AMD and NVidia, but also on the latest processors of Intel and AMD, and even processors in smartphones and tablets. Special processors such as DSPs and FPGAs will get support too. As it is an open standard the support will only grow.
Offered services
StreamHPC has been active since June 2010 as acceleration-specialist and offers the following services:
[list2]
- development of extreme fast software,
- design of (faster) algorithms,
- accelerating existing software, and
- provide training in OpenCL and acceleration-tecniques.
[/list2]
Not many companies master this specialisms and StreamHPC enjoys worldwide awareness on top of that. To provide support for large projects, collaborations with other companies have been established.
The preferred way of working is is a low hourly rate and agreed bonuses for speed-ups.
Target markets
The markets we operate in are bio-informatics, financial, audio and video, hightech R&D, energy, mobile apps and other industries who target more performance per Watt or more performance per second.
WBSO
What we offer suits WBSO-projects well (in Netherlands only). This means that a large part of the costs can be subsidised. Together we can promote new technologies in the Netherlands, as is the goals of this subsidy.
Contact
Call Vincent Hindriksen MSc at +31 6 45400456 or mail to vincent@StreamHPC.nl with all your questions, or request a free demo.
Download the brochure for more information.



 Say you have a device which is extremely good in numerical trigoniometrics (including integrals, transformations, etc to support mainly Fourier transforms) by using massive parallelism. You also have an optimised library which takes care of the transfer to the device and the handling of trigoniometric math.
Say you have a device which is extremely good in numerical trigoniometrics (including integrals, transformations, etc to support mainly Fourier transforms) by using massive parallelism. You also have an optimised library which takes care of the transfer to the device and the handling of trigoniometric math.













 e-mail:
e-mail: 
 The Ifc6410 is a $149 costing single-board computer with Adreno 320 and Qualcomm Snapdragon S4 Pro – APQ8064.
The Ifc6410 is a $149 costing single-board computer with Adreno 320 and Qualcomm Snapdragon S4 Pro – APQ8064.
 The
The 






 At StreamHPC, there is broad experience in the parallel, high-performance implementation of image filters. We have significantly improved the performance of various image processing software. For example, we have supported Pixelmator in achieving outstanding processing speeds on large image data, and users frequently praise the software’s speed in comparisons with competing software products.
At StreamHPC, there is broad experience in the parallel, high-performance implementation of image filters. We have significantly improved the performance of various image processing software. For example, we have supported Pixelmator in achieving outstanding processing speeds on large image data, and users frequently praise the software’s speed in comparisons with competing software products.



