 A while ago macresearch.com stopped from existing, as David Gohara pulled the plug. Luckily the sources of a very nice tutorial were not lost, and David gave us permission to share his material.
A while ago macresearch.com stopped from existing, as David Gohara pulled the plug. Luckily the sources of a very nice tutorial were not lost, and David gave us permission to share his material.
Even if you don’t have a MAC, then these almost 5 year old materials are very helpful to understand the basics (and more) of OpenCL.
We also have the sources (chapter 4, chapter 6) and the collection of corresponding PDFs for you. All material is copyright David Gahora. If you like his style, also check out his podcasts.
Introduction to OpenCL
OpenCL fundamentals
Building an OpenCL Project
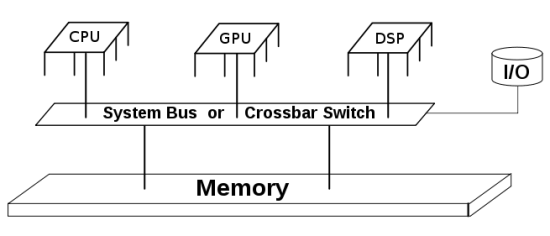
Memory layout and Access
Questions and Answers
Shared Memory Kernel Optimisation
Did you like it? Do you have improvements on the code? Want us to share more material? Let us know in the comments, or contact us directly.
Want to learn more? Look in our knowledge base, or follow one of our trainings.



 The research lab
The research lab 
 Altera has just released the free ebook FPGAs for dummies. One part of the book is devoted to OpenCL, so we’ll quote some extracts here from one of the chapters. The rest of the book is worth a read, so if you want to check the rest of the text, just
Altera has just released the free ebook FPGAs for dummies. One part of the book is devoted to OpenCL, so we’ll quote some extracts here from one of the chapters. The rest of the book is worth a read, so if you want to check the rest of the text, just 

 When copying data from global to local memory, you often see code like below (1D data):
When copying data from global to local memory, you often see code like below (1D data):



 So, for this year it will be K40. Here’s an overview:
So, for this year it will be K40. Here’s an overview:

 At Intel they have CPUs (Xeon, Ivy Bridge), GPUs (Isis) and Accelerators (Xeon Phi). OpenCL enables each processor to be used to the fullest and they now promote it as such. Watch the below video and see their view on why OpenCL makes a difference for Intel’s customers.
At Intel they have CPUs (Xeon, Ivy Bridge), GPUs (Isis) and Accelerators (Xeon Phi). OpenCL enables each processor to be used to the fullest and they now promote it as such. Watch the below video and see their view on why OpenCL makes a difference for Intel’s customers.
 Khronos just announced three OpenCL based releases:
Khronos just announced three OpenCL based releases:












 On 15 – 17 April 2014 a 3-day workshop around HPC is organised. It is free, and focuses on bringing industry and academy together.
On 15 – 17 April 2014 a 3-day workshop around HPC is organised. It is free, and focuses on bringing industry and academy together.








